Here is an example of an elastic object wrapper in ruby
1 | class ElasticObject |
Here is an example of an elastic object wrapper in ruby
1 | class ElasticObject |
So, I had to convert a hash into an open struct to make accessing things easy. Here is the code.
1 |
|
I just started playing with Coreos to run my docker containers.
However, when I spun up an instance on Digital Ocean with my private key,
I wasn’t able to login using the root account. It turns out that Digital Ocean sets up the private key
for an account with the name core. So, the next time you are stuck doing this just try logging in with
the core account.
1 | ssh core@<your-ip> |
In the past I struggled with having a consistent strategy for showing error messages in javascript. In rails we usually put the error/success messages in the flash, However if the request is an ajax request the flash doesn’t get used and the message shows up on the next page load.
The following code shows error/success messages using the flash properly
1 | #app/classes/ajax_flash.rb |
Include this javascript code
1 | (function(){ |
To use this you just need to use your normal code with respond_to
1 | def create |
Today I saw a submission on HN about formspree.com which allows you to setup a form on your site similar to google forms / wufoo but without an iframe, so you can tweak it as much as you like. A quick whois lookup shows that this domain was created on 17 Feb 2014 which is just a few days ago. I had launched a similar service called http://getsimpleform.com/ almost 2 years ago. It differs with formspree in a few aspects though. When I was thinking about creating simpleform, I didn’t want to expose the users email to the public by putting it in a form as formspree does, it is just a design choice I made. getsimpleform also has spam prevention using akismet and allows you to create forms with file uploads. So, it is a bit more feature rich then formspree.
However, the point I am trying to make here is about the impact of a good looking visual design on how users perceive your product. Formspree has 209 upvotes (at the time of this post) and getsimpleform.com posts (5 submissions all of which were made by me) have a sum of 7 upvotes. Look at the difference in their screenshots.

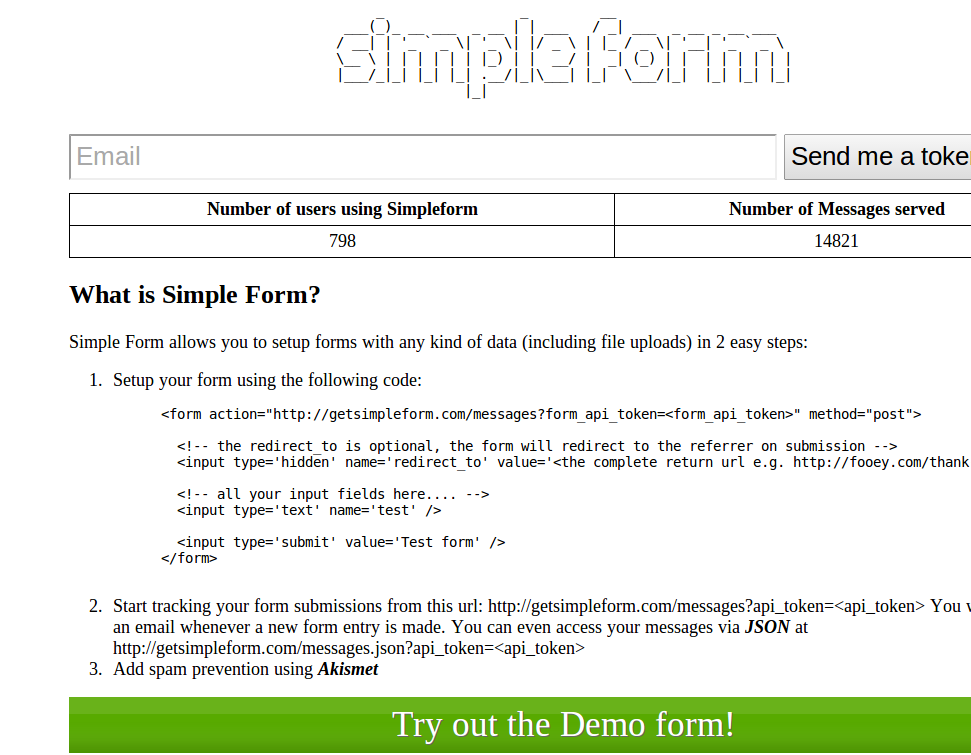
I had made the design simple just to convey the ‘Simple’ theme, but it seems to have backfired on the impression it makes on users. I will spend time and make the interface a bit more shiny. I hadn’t expected the HN crowd to go by appearances. Good to learn new lessons.
My best wishes to the formspree folks
I have a big library of music with a lot of songs I don’t like anymore or songs which were a part of an album from which there was one song which I liked. And whenever my music player starts playing these songs, I hit a keyboard combo which goes to the next song. But these songs would be in my library just waiting to annoy me again. Here is a little ruby script which I wrote from an idea by my friend Abdul Sattar.
1 |
|
I also have a keyboard shortcut bound to it which triggers it.
1 | , ((modMask, xK_x ), spawn "/home/minhajuddin/Dropbox/private/scripts/remove-current-song &> /tmp/log") -- %! Remove music from library |
Now whenever banshee plays a song which I don’t like I can remove it from my library forever by just hitting ‘Windowx+x’
The pg_dump command runs on your prod server streaming all the data into pg_restore which runs locally
1 | ssh user@remote.com pg_dump -Fc --no-acl --no-owner remote_db | pg_restore --verbose --clean --no-acl --no-owner -d localdb |
Cloud computing is mostly a buzzword. In the old days when people wanted a server to put run their software on it (like a website), they used to order a dedicated (also called bare metal) server with a hosting company (like rackspace.com), these companies would setup a server with your configuration and then give you access to it so that you could put your software and use it anyway you want. This usually would take days and the server companies needed upfront payments for setup and monthly fees for server costs. So, if you wanted to put a website for a week for a small conference you would have to pay for the setup and the fee for the minimum rent duration (which would typically be a month).
With this kind of setup it used to be hard for website developers/maintainers to scale their website. Scaling usually means adding more servers to your setup or adding more resources (CPUs/RAM etc,.) to your existing servers, to be able to handle an increase in traffic to your website or software.
With the advancement of technologies, and with the inception of virtualization, hosting providers have become more flexible. Virtualization technologies allow you to have any number of ‘virtual servers’ running on any number of ‘real/physical servers’. So, you can have one real computer running two ‘virtual servers’, one might be a linux operating system and another a windows operating system simultaneously. Virtualization is useful because not all servers run at their full capacity all the time. So, if there are two ‘virtual servers’ running on one physical server, they share their resources (CPU, RAM etc,.) and since they are not using all their resources all the time, the resources can be shared. The important thing about virtualization is that you can create as many virtual servers as you want (as long as your hardware can handle the load) very easily. So, this has allowed hosting providers to setup huge clusters of hardware running virtualized servers on top of them. So, now if you want a virtual server, it will be ready at the click of a button. You can even create a virtual server, increase its RAM size by running a simple command. This allows web developers and administrators to automatically increase the number of servers when their is an increase in traffic and shutdown servers when there is less traffic. And since you only pay for the amount of time your servers are running and not by months, you can have efficient setups without wasting your money. If you had a supermarket wouldn’t it be awesome if you had 100 checkout lanes when you had a huge amount of customers (on weekends) and only 1 when there are no customers? Virtualization/Cloud computing allows web administrators to do this.
More information can be found here:
HTTP is a protocol used by computers to communicate with each other. A protocol is just a series of rules/steps which need to be followed for communication. e.g. If you want to buy a chocolate from the mall, you can go to the mall, find the chocolate put it in a shopping cart, go to the checkout counter and pay the bill. This can be thought of as a protocol, In this example, the steps are not very strict, but in computer protocols there is no scope for ambiguity.
HTTP is used whenever you visit a website. HTTP lays out the rules the communication between your browser and the web server. Here is an example of what happens when you open enter cosmicvent.com in your browser and hit enter:
1) The browser finds the IP address of cosmicvent.com (which at the moment is 176.9.113.5). 2) It sends it a text message using another protocol called TCP/IP. The message looks something like this:
GET / HTTP/1.1
Host: cosmicvent.com
Connection: keep-alive
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.63 Safari/537.31
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8,hi;q=0.6,te;q=0.4
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
Cookie: __utma=223412489.1036637458.1339923857.1366442947.1368767056.19; __utmz=223412489.1339923857.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)
This is called an HTTP ‘Request’, It says that the browser is ‘making’ a ‘GET’ request using the ‘HTTP/1.1’ protocol and that the browser is looking for a ‘document’ called ‘/‘ of type ‘html’ or ‘xhtml’. The ‘User-Agent’ has information about the version of the browser.
3) Now, the webserver which is the software running on google sends an HTTP ‘Response’ which looks like the following:
HTTP/1.1 200 OK
Server: nginx/1.0.11
Content-Type: text/html; charset=utf-8
Keep-Alive: timeout=20
Status: 200 OK
Cache-Control: max-age=60, private
X-UA-Compatible: IE=Edge,chrome=1
ETag: "39a5d8d65c963b21615df87157699c2e"
X-Request-Id: 8a9bce4126abb10ca9fdd1e76a1ea520
X-Runtime: 0.059963
X-Rack-Cache: miss
Transfer-Encoding: chunked
Date: Sun, 19 May 2013 17:38:22 GMT
X-Varnish: 2087699445
Age: 0
Via: 1.1 varnish
Connection: keep-alive
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<!--[if lt IE 7 ]> <html class="ie6" xmlns="http://www.w3.org/1999/xhtml"> <![endif]-->
<!--[if IE 7 ]> <html class="ie7" xmlns="http://www.w3.org/1999/xhtml"> <![endif]-->
<!--[if IE 8 ]> <html class="ie8" xmlns="http://www.w3.org/1999/xhtml"> <![endif]-->
<!--[if IE 9 ]> <html class="ie9" xmlns="http://www.w3.org/1999/xhtml"> <![endif]-->
<!--[if (gt IE 9)|!(IE)]><!--> <html xmlns="http://www.w3.org/1999/xhtml"> <!--<![endif]-->
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<link rel="sitemap" type="application/xml" title="Sitemap" href="/sitemap.xml" />
<title>
Home - Cosmicvent Software
</title>
Now this text is understood by the browser, the browser reads the header which is the part above the empty line (above <!doctype html>). The response says that the server is also using the ‘HTTP/1.1’ protocol, the 200 and OK mean that the response was ‘successful’ and it didn’t fail (The 200 is a status code, and HTTP has many status codes with different meanings, you might have seen 404 Not found in a browser, that means the document requested by the browser could not be found by the webserver). It also tells us when this document was sent, and some more information which is understood by the server. Another important Header is the ‘Content-Type’ which tells the browser what type of document the response is. In this example it says the content type is an html document. So, the browser renders it as an html page. If the content type was an image, the response would have something like: ‘Content-Type: image/png’, which would tell the browser to render it as an image. What follows after the empty line (the <!doctype html>…) is the actual content.
An analogy for an HTTP Response is a mail package. The cover of the mail package has information about the package like the weight of the package, the address to which it is to be delivered, its contents. And when you open the package it contains the actual items. An HTTP response is similar but it has different information in the ‘Header’ (the package wrapping). This information is sometimes also called meta data. And, the actual document comes after an empty line after the header.
You can read more about HTTP here: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
Angularjs loads the templates used through the [ng-include] (http://docs.angularjs.org/api/ng.directive:ngInclude) directive on the fly. This might cause a lot of requests to be made to your server which is not a good thing.
This solution allows you to load all your templates in one go and it will actually shove all your templates into your final application.js file.
GOTCHA: If you use this approach you will have to change this file whenever a template changes in development, if you don’t it won’t recompile this file which will cause your app to use old templates. This happens only in development and it’s a pain, I don’t know how to solve it yet. Anyone who knows can help me out here :)
Update:
Steven Harman has shared a solution which uses depend_on, I have amended my script to use it.
1 | //app/assets/javascripts/ngapp/templates.js.erb |
This loads all the templates from your /app/assets/templates directories which have an extension .haml. And you can use templates just using their filename without the haml extension. e.g. a template called app/assets/templates/filter.html.haml can be included using
1 | %div(ng-include="'filter.html'") |
Make sure you have //= require ./templates in your application.js and that you include 'templates' as a dependency in your angular module
1 | AA.root = angular.module('root', [.., 'templates',..]) |
I am planning to participate in the Google Code Jam this year. And I have been working on the practice problems. It’s been fun, It’s a great feeling when you are able to solve a challenging problem after spending time on it.
My strategy for solving problems is simple: First I try the brute force approach, Once I have a solution, I start thinking of a more efficient way to do it. I have since realized that spending some time thinking about the problem before butting your head against it is way more helpful. When I reached the Minimum Scalar Product problem.
You are given two vectors v1=(x1,x2,…,xn) and v2=(y1,y2,…,yn). The scalar product of these vectors is a single number, calculated as x1y1+x2y2+…+xnyn.
Suppose you are allowed to permute the coordinates of each vector as you wish. Choose two permutations such that the scalar product of your two new vectors is the smallest possible, and output that minimum scalar product.
I thought for a moment and came up with the idea that I needed all possible combinations of the first vector with a constant ordered second vector. This algorithm had an order of O(n!). I just jumped into coding and started solving it. Here is the ugly mess of code I came up with:
1 | class MinimumScalarProduct |
Here is an example test file if you want to try it.
Then, I started actually thinking about the problem. After a few minutes it became clear to me that all I had to do, to get a minimum product, was order the two vectors in opposing orders of magnitude. And with this understanding I could solve it much more easily and with an algorithm with an order of O(nlogn).
1 | lines = File.readlines(ARGV.first || 'A-small-practice.in').map{|x| x.chomp} |
In the past I have used brute force to solve problems where the time didn’t matter (I could always move it to a background process if the time mattered), but it’s a nice feeling to be able to be able to solve problems by simply thinking. Sometimes we(software developers) are so addicted to the quick feedback cycle of coding that we fail to spend time thinking of the problem/solution.
I had to write some code to see if the input time slots on a given day overlapped. I gave this problem to my sister, to come up with an algorithm. She came up with a nice solution which hadn’t crossed my mind. See, if your solution is as good as hers :)
#sample containing overlapping times
[{:start_time=>'2013-02-20 00:00:00', :end_time=>'2013-02-20 01:00:00'},
{:start_time=>'2013-02-20 02:00:00', :end_time=>'2013-02-20 03:00:00'},
{:start_time=>'2013-02-20 07:30:00', :end_time=>'2013-02-20 09:00:00'},
{:start_time=>'2013-02-20 04:30:00', :end_time=>'2013-02-20 05:00:00'},
{:start_time=>'2013-02-20 04:10:00', :end_time=>'2013-02-20 06:00:00'},
{:start_time=>'2013-02-20 01:00:00', :end_time=>'2013-02-20 02:00:00'},
{:start_time=>'2013-02-20 03:00:00', :end_time=>'2013-02-20 04:00:00'},
{:start_time=>'2013-02-20 07:00:00', :end_time=>'2013-02-20 08:00:00'},
{:start_time=>'2013-02-20 06:00:00', :end_time=>'2013-02-20 07:00:00'},
{:start_time=>'2013-02-20 09:00:00', :end_time=>'2013-02-20 10:00:00'}]
#sample without overlapping times
[{:start_time=>'2013-02-20 00:00:00', :end_time=>'2013-02-20 01:00:00'},
{:start_time=>'2013-02-20 07:00:00', :end_time=>'2013-02-20 08:00:00'},
{:start_time=>'2013-02-20 06:00:00', :end_time=>'2013-02-20 07:00:00'},
{:start_time=>'2013-02-20 01:00:00', :end_time=>'2013-02-20 02:00:00'},
{:start_time=>'2013-02-20 08:00:00', :end_time=>'2013-02-20 09:00:00'},
{:start_time=>'2013-02-20 03:00:00', :end_time=>'2013-02-20 04:00:00'},
{:start_time=>'2013-02-20 04:00:00', :end_time=>'2013-02-20 05:00:00'},
{:start_time=>'2013-02-20 05:00:00', :end_time=>'2013-02-20 06:00:00'},
{:start_time=>'2013-02-20 02:00:00', :end_time=>'2013-02-20 03:00:00'},
{:start_time=>'2013-02-20 09:00:00', :end_time=>'2013-02-20 10:00:00'}]
1 | def times_overlap?(times) |
I have read How to Win Friends & Influence People a few years ago, It’s an amazing book filled with great advice on how to talk to people. However, I have ended up using it on the wrong people, I’ve found myself sugar coating a lot of stuff when I communicate.
Sugar coating stuff is great when you are talking to strangers or people whom you don’t communicate with a lot. But, when you do that with your family, the people you work with, it increases the noise in your communication. For instance, if I compliment my mother on the food, she just thinks I am trying to be nice, because I always complement her. Nowadays, everyone is trying to peel of the layer of my bullshit sugar coating to see what I mean. It has reached a point where, If I don’t talk to my folks for a day they think I am mad at them, because of something they did.
I read something about this a while ago, but I didn’t understand the full extent of it. It’s like the story about the author who wrote:
The hero opened a blue door and walked into the room.
The reader thinks blue door signifies that the hero must be feeling down. Even when it’s just a bloody blue door. It doesn’t have any frigging meaning to it. People end up trying to read between the lines even when there is nothing to read.
I have learnt a valuable lesson from all of this. Don’t make it difficult for people to understand what you are saying. Especially your family, friends and colleagues. You might end up hurting them without even knowing. And, end up an unconscious player in a game of hide and seek with your words
As a programmer, you should always thinking about automating your grunt work. My family has a private google group where we share/discuss stuff (I know what you are thinking, sharing through email ugh.. but that’s how it is). Whenever I wanted to share I used to copy the link, hit Ctrl+D to get the bookmark save box, copy the title from that and then use that as a subject to send an email, so, here is a script I wrote to automate that.
1 | javascript:(function(){window.location.href = "mailto:fooxxxx@googlegroups.com?subject="+document.title+"&body="+window.location.href;})() |
Just change the email in the above script to be sent to the group you want and add it as a bookmarklet
I have done my share of bash scripting, but for the life of me I couldn’t get a color bash prompt working. I used to wire it with code like: PS1="\e[0;31m[\u@\h \W]\$ \e[m " (I got it from sites like cyberciti. And these would never work, it would color the prompt alright, but it would screw up the cursor position. Today, I found that this syntax is actually used to set the cursor position. Anyway, I finally have a bash color prompt working without screwing up my cursor position here it is:
1 | #~/.bashrc |
Most of the code here is for coloring the prompt, you can read more about it at the excellent archlinux wiki
Screenshot:

Today while walking to my home from my office, I purchased a bottle of orange juice. I was a bit bored and started tossing it in the air (if throwing it 15cm in the air can be called tossing :) ). As I reached a stretch of road without people, I started tossing it higher, maybe a few meters in the air. I felt happy doing this. However, on the next turn, I saw a couple of guys talking on the sidewalk, I stopped tossing. I thought I would resume once I was past these guys. The reason I stopped was very obvious, I didn’t want these guys to watch me toss the bottle and fail to catch it. Then I started thinking, I always used to say ‘Do not be afraid’. Back in the day, I even had a poster stuck on my wall which read ‘Do not be afraid’. And here I was, afraid of what two strangers would think if I dropped the bottle (which is such a trivial thing but that’s not the point).
It is astounding how we are afraid to do simple things even in complete anonymity. These guys really didn’t know me, and even if I failed to catch the bottle, it had no real consequences, they were probably not even looking or thinking about it.
So, here I was afraid of experimenting with a trivial thing, inspite of all my beleifs. Then it hit me, the more you fear, the lesser you experiment and the lesser you experiment the lesser you grow. Experimentation takes courage.
The human mind is such a complex thing, and we can only grow if we learn about our true selves instead of living in a state of denial. So, experiment with gay abandon, don’t be afraid of the consequences. No one is really paying attention to every little action you do. Even if they are there are really no consequences most of the time.
Now, that I know my weakness, I hope to overcome it and be able to experiment a little more regardless of the consequences(real or imaginary).
As they say, Knowing that you don’t know something is the most important stage of learning. I have hopefully reached this stage, I can’t say for sure though, there are many things which we say which we don’t fully comprehend. It is like seeing an important detail which you missed while watching a movie the first time. Wise words have layers of meaning hidden under them. Everytime you think you have understood them completely, they show you more by uncovering another layer.
If you don’t let your kids experiment and explore this world, you are limiting their growth. It is your job to expose them to all the things in the world. One of the huge problems in Indian education is that most of the kids don’t know what they need or love till they graduate. There are many who don’t know what they love even till they die. I am not talking about the kind of food you like. I am talking about much bigger things. For instance, my sister who is 20 years old, has just found that she loves cooking. Think about it for a second, she is an Indian girl, she has access to a kitchen, and it still took 20 years for her to find that she loves cooking. Obviously it is because she hasn’t tried cooking before.
So, as parents it is your responsiblity to expose your children to as many things as possible.
Explore, experiment, toss a frigging bottle. Do not be afraid.
P.S: By the way, I didn’t stop tossing the bottle till I reached my home :)
For the trainees :)
B <= current branch
D <= Commands to run on developer's computer
R <= Commands to run on reviewer's computer
# <= comment
1 Update your master
B: master D: git checkout master
B: master D: git fetch origin
B: master D: git merge origin/master #this will never create merge conflicts
because it is a fast forward (straight line)
2 Create topical branch and add features/commits
B: master D: git checkout -b foo
B: foo D: #make all your feature commits
2.1 This is an optional step, which you can do if your feature is taking a long time.
This will reduce your merge conflict pain down the line
D: Update master, see step #1
B: master D: git checkout foo
B: foo D: git merge master
3 Review
B: foo D: git push origin foo
B: foo R: git fetch
B: foo R: git checkout -t origin/foo
B: foo R: #add notes or refactor
B: foo R: #add commits on foo
B: foo R: git push origin foo
4 Merge review notes or refactored code
B: foo D: git fetch origin
B: foo D: git merge origin/foo
B: foo D: #make more commits/features
#Repeat 3-4 as many times as you need
5 Merge into master
D: Update master, see step #1
#Merge topical branch into master
B: master D: git checkout foo
B: foo D: git merge master #this step might cause merge conflicts
B: foo D: #resolve the conflicts
B: foo D: git checkout master
B: master D: git merge foo #this won't cause any conflicts
6 Push your code to origin
B: master D: git push origin master
Steps #5 and #6 should be done in a small time window
Update: Changed git checkout origin/foo -b foo to git checkout -t origin/foo from a tip on HN
The temptation to be clever while programming is very high. You want to show off or use your mad skills to create the most clever piece of code. It gives you a sense of satisfaction which very few things do. However, I’ve found like most people that it’s not the best thing to do for the long term maintainability of projects.

Languages like ruby, being very powerful, make this very easy. Like they say with great power comes great responsibilty. So, this is some advice for young devs: Create the cleverest piece of code in your personal, fun projects to satiate your hunger, but when it comes to projects for customers, you owe it to them to be sensible and write mundane code
Here is a small example of clever vs mundane code.
###Clever code
1
2
3def address_is_empty?(customer)
[:street, :city, :state, :zip].any?{|method| customer.send(method).nil? || customer.send(method).squish.empty? }
end
###Mundane code
1
2
3def address_is_empty?(customer)
[customer.street, customer.city, customer.state, customer.zip].any?{|prop| prop.nil? || prop.squish.empty? }
end
Use the vba package or add the command-t git directory to your vim rtp using pathogen. I use pathogen, hence the following
1 | #download the code |